此篇文章是学习分析 objc-msg-arm64.s 源码过程中需要用到的汇编知识的一点记录
字节序
在内存中有两种字节排布顺序,大端序(BE)或者小端序(LE)。两者的主要不同是对象中的每个字节在内存中的存储顺序存在差异。一般X86中是小端序,最低的字节存储在最低的地址上。在大端机中最高的字节存储在最低的地址上。
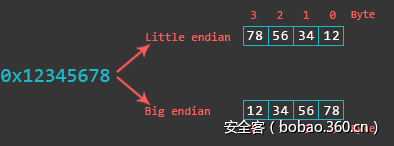
在版本3之前,ARM使用的是小端序,但在这之后就都是使用大端序了,但也允许切换回小端序。在我们样例代码所在的ARMv6中,指令代码是以[小端序排列对齐]。但是数据访问时采取大端序还是小端序使用程序状态寄存器(CPSR)的第9比特位来决定的。
寄存器
ARM 32位处理器有16个寄存器,从 r0 到 r15,每一个都是32位比特。调用约定指定他们其中的一些寄存器有特殊的用途,例如:
- r0-r3:用于存放传递给函数的参数;
- r4-r11:用于存放函数的本地参数;
- r12:是内部程序调用暂时寄存器。这个寄存器很特别是因为可以通过函数调用来改变它;
- r13:栈指针sp(stack pointer)。在计算机科学内栈是非常重要的术语。寄存器存放了一个指向栈顶的指针。看这里了解更多关于栈的信息;
- r14:是链接寄存器lr(link register)。它保存了当目前函数返回时下一个函数的地址;
- r15:是程序计数器pc(program counter)。它存放了当前执行指令的地址。在每个指令执行完成后会自动增加;
ARM寄存器 r0, r1, r2, r3四个寄存器是用来传递参数的; r4, r5, …, r11这些寄存器是通用的,在函数内部可以使用,但是用完需要恢复,所以一般函数里面会先把需要使用的寄存器入栈,比如如要使用r7作为临时变量,那么会有下面的调用: push {r7, lr} 即把r7和返回地址入栈,等到函数要返回前,再出栈恢复r7寄存器。 pop {r7, lr} r12 r13:sp栈指针寄存器,ARM使用FD栈,sp指向栈顶数据,且向下增长。 r14:lr保存返回地址——即调用该函数后下一条指令的地址 r15:pc——当前执行的指令地址
64位处理器有34个寄存器,包括31个通用寄存器、SP、PC、CPSR。
| 寄存器 | 位数 | 描述 |
|---|---|---|
| x0-x30 | 64bit | 通用寄存器,如果有需要可以当做32bit使用:wO-w30 |
| FP(x29) | 64bit | 保存栈帧地址(栈底指针) |
| LR(x30) | 64bit | 通常称 x30 为程序链接寄存器,保存子程序结束后需要执行的下一条指令 |
| SP | 64bit | 保存栈指针,使用 SP/WSP 来进行对 SP 寄存器的访问。严格来说叫栈顶指针,永远指向栈的顶部。 |
| PC | 64bit | 程序计数器,俗称 PC 指针,总是指向即将要执行的下一条指令,在 arm64 中,软件是不能改写 PC 寄存器的。 |
| CPSR | 64bit | 状态寄存器 |
x0-x7: 用于子程序调用时的参数传递,
x0还用于返回值传递x0 - x30是31个通用整形寄存器。每个寄存器可以存取一个64位大小的数。 当使用r0 - r30访问时,它就是一个64位的数。当使用w0 - w30访问时,访问的是这些寄存器的低32位
浮点寄存器
因为浮点数的存储以及其运算的特殊性,CPU提供浮点数寄存器来处理浮点数;
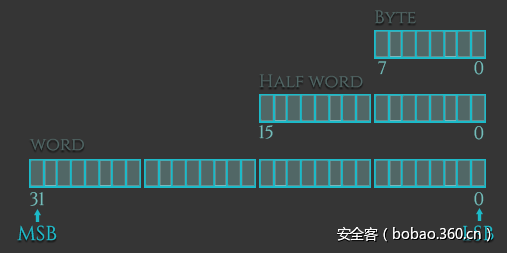
128位的浮点向量寄存器可分为5种:
- 用作8位寄存器时记作 :Bn; (Byte,字节)
- 用作16位寄存器时记作 :Hn; (Half Word,半字)
- 用作32位寄存器时记作 :Sn; (Single Word,单字)
- 用作64位寄存器时记作 :Dn; (Double Word,双字)
- 用作128位寄存器时记作:Qn; (Quad Word,四字)
n=0 … 30;
伪操作
.text:
段保存代码,是只读和可执行的,后面那些指令都属于 .text 段。
.global
让一个符号对链接器可见,可以供其他链接对象模块使用。
.extern
.extern FUNC 说明 FUNC 为外部函数,调用的时候可以遍访所有文件找到该函数并且使用它。
.section
分段,用户可以通过 .section 伪操作来自定义一个段
1 | .section expr; // expr 可以是 .text/.data/.bss |
.quad
定义8字节的数据
常用指令
b
b {条件} 目标地址
b 指令是最简单的跳转指令。一旦遇到一个 b 指令,ARM 处理器将立即跳转到给定的目标地址,从那里继
续执行。注意存储在跳转指令中的实际值是相对当前 PC 值的一个偏移量,而不是一个绝对地址,它的值由汇编器来计算(参考寻址方式中的相对寻址)。它是 24 位有符号数,左移两位后有符号扩展为 32 位,表示的有效偏移为 26 位(前后32MB 的地址空间)。以下指令:
1 | b Label //程序无条件跳转到标号 Label 处执行 |
bl
branch with link
bl{条件} 目标地址
bl 是另一个跳转指令,但跳转之前,会在寄存器 r14(lr) 中保存 pc 的当前内容,因此,可以通过将 r14 的内容重新加载到 pc 中,来返回到跳转指令之后的那个指令处执行。该指令是实现子程序调用的一个基本但常用的手段。以下指令:
1 | bl Label //当程序无条件跳转到标号 Label 处执行时,同时将当前的 pc 值保存到 r14 中 |
bx
bx{条件} 目标地址
跳转到指令中所指定的目标地址,目标地址处的指令既可以是 ARM 指令,也可以是 Thumb 指令。
blx
blx 指令从 ARM 指令集跳转到指令中所指定的目标地址,并将处理器的工作状态有 ARM 状态切换到 Thumb 状态,该指令同时将 pc 的当前内容保存到寄存器 r14 中。因此,当子程序使用 Thumb 指令集,而调用者使用ARM 指令集时,可以通过 BLX 指令实现子程序的调用和处理器工作状态的切换。
br
无条件的跳转命令,用于跳转到 reg 内容地址
adrp
计算指定的数据地址到当前pc寄存器值相对偏移
movw
mov word,把16位立即数放到寄存器的底16位,高16位清0
movt
把16位立即数放到寄存器的高16位,低16位不影响
movs
用一个字节长度值来填充寄存器
ldr
把数据从内存中某处读取到寄存器;mov不能实现这个功能,mov只能在寄存器之间移动数据,或者把立即数移动到寄存器中
ldp/stp
从栈取/存数据
1 | ldp x29, x30, [sp], #16; // 把 x29, x30的值存到 sp-16的地址上,并且把 sp-=16. |
SBFX/UBFX
有符号和无符号位域提取。 将一个寄存器中相邻的位复制到另一个寄存器的最低有效位,并用符号或零扩展到 32 位。
1 | op{cond} Rd(目标寄存器), Rn(源寄存器), #lsb, #width |
不要将 r15 用作 Rd 或 Rn。
cmp
cmp 操作对象1, 操作对象2
计算 操作对象1 - 操作对象2 但不保存结果,只是根据结果修改相应的标志位。
cbz/cbnz
cbz比较,为零则跳转;
cbnz比较,为非零则跳转。
UXTH
无符号(Unsigned)扩展一个半字(Half)到 32位,相当于左移 4 位。
ret
返回;默认使用 lr 寄存器的值,通过底层指令指示 CPU 此处作为下条指令地址
使用例子
1 | mov r0, r1 => r0 = r1 |
1 | ldr = 加载字,宽度四字节 |
分析样例
样例一
1 | int addFunction(int a, int b) { |
1 | .globl _addFunction |
- .号开始的行都不是汇编指令而是作用于汇编器,可忽略
- 以冒号为结束的行,是汇编的标签,作用是方便代码进行路由而无需知道指令的位置;当链接生成二进制文件的时候,链接器会将标签转换成实际内存地址
- 在汇编代码之后,以@开头的是对应代码文件的行数
忽略掉注释和标签,重要的代码如下:
1 | _addFunction: |
- 分配 12 个字节长度的内存,sp = sp - 12
r0和r1存放着函数的2个参数,如果入参有四个参数,那么r2和r3就会分别存放第三和第四个参数。如果函数超过四个参数,或者一些例如结构体的参数超过了32位比特,那么参数将会通过栈来传递。这里通过 str 指令将r0和r1存储的值保存到 sp+8 和 sp+4 的栈内存位置- 和
str指令相反的,ldr指令是从一个内存中加载内容到寄存器。这里分别将栈内存 sp+8 和 sp+4 的值赋值给r0和r1,这里和2重复了,编译器会对这里进行优化 - r0 = r0 + r1
- *sp = r0, ro = *sp,重复操作会被编译器优化
- sp 指针地址增加12字节,sp = sp + 12,作用是为了回收步骤1申请的内存
- 返回到调用函数,
lr(link register)存放了调用函数执行完当前函数(addFunction)的下一条指令
样例二
1 | __attribute__((noinline)) |
1 | _fooFunction: |
r7和lr被推入到栈,意味着sp(栈指针)减掉了8字节(栈指针始终指向栈顶,所以在 push 的时候会变小),因为r7和lr都是4字节。栈指针向低地址增长而且通过一个指令存储了两个值。r7的值需要存储起来的原因是之后函数执行时它会被使用到并重写。- 通过 movs 指令将常量读取到
r0和r1中(r0=12, r1=34),这里用 movs 是直接以一个字节的长度去读取值并填充到寄存器中。此时r0和r1就是函数 addFunction 的2个参数 - 调用函数 addFunction 前,先将
sp(栈指针) 保存起来,又因为r7寄存器存放函数的本地参数。你会发现剩余的函数代码中并没有使用栈指针或者r7,因此这是个小小的多余处理。有时候开启了优化也优化不掉。 - 执行
bl指令调用函数 addFunction,lr(链接寄存器)置为当前函数的下一个指令。 - 此时
r0保存了 addFunction 函数的返回值(样例一 @5),这个值会作为 printf 函数的第二个参数,所以用 mov 赋值给r1 - printf 函数的第一个参数是一个字符串。这三条指令作用是将字符串的开始地址的指针到
r0寄存器。字符串存储在二进制文件中的『数据段』,只有最终二进制被链接时才能知道该数据的具体位置。字符串可以在main.m 生成的目标文件例找到。如果你在生成的汇编代码内搜索L.str,便可找到它。前两个指令加载常量的地址,并减去标签的地址(LPC1_0+4字节,add r0, pc指令占用4个字节)。r0 = r0 + pc(程序计数器),这样无论L.str在二进制文件的什么位置都能够准确的存放字符串的位置。 下面的图展示了内存分布。L_.str - (LPC1_0 + 4)差值可以随便变动,但是加载r0的代码却不用变化。 blx跟bl略有区别,x代表处理器工作状态。- 最后一条指令是推出第一条指令推入的值。这次寄存器的值是用栈中的值填充的,且栈指针增加了。回想下,
r7和lr之前是被推入到栈中,那么此时为何是推出来的值存入到了r7和pc中,而不是r7和lr呢? 好的,记得lr是存储当前函数执行完成后的下一个指令地址吧。当你把lr推出栈赋值给pc后,执行将会从本函数调用的地方继续执行。这通常是一个函数返回的实现方式,而不是像addFunction那样切分支的方式。
参考文章: